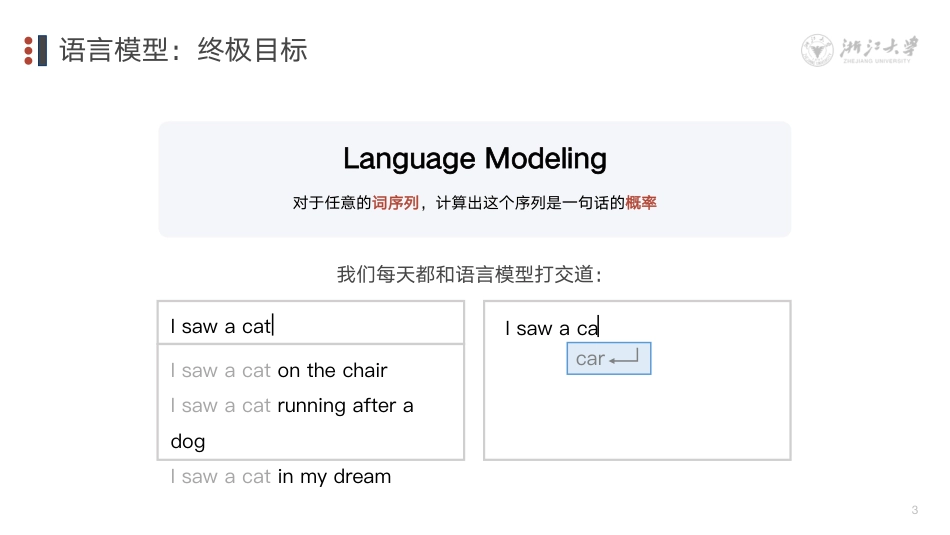
1浙江大学DS系列专题主讲人:朱强浙江大学计算机科学与技术学院人工智能省部共建协同创新中心(浙江大学)https://person.zju.edu.cn/zhuqDeepSeek技术溯源及前沿探索2一、语言模型三、ChatGPTOutline四、DeepSeek五、新一代智能体二、Transformer3LanguageModeling对于任意的词序列,计算出这个序列是一句话的概率我们每天都和语言模型打交道:IsawacatIsawacatonthechairIsawacatrunningafteradogIsawacatinmydreamIsawacacar语言模型:终极目标4Sheismymom1000010000100001One-hotEncoding只有一个1,其余均为0One-hotEncoding有什么缺点吗?编码:让计算机理解人类语言语言模型:基本任务50.990.990.050.1…0.990.050.930.09…0.020.010.990.98…0.980.020.940.3…鲸鱼海豚鹦鹉企鹅游泳飞翔WordEmbedding用一个低维的词向量表示一个词能使距离相近的向量对应的物体有相近的含义20维的向量用one-hot和wordembedding的方法分别可以表示多少单词?编码:让计算机理解人类语言6WordEmbedding结合句子语境我们可以猜测:tezgüino是一种由玉米制作的酒精类饮料Abottleoftezgüinoisonthetable.Everyonelikestezgüino.Tezgüinomakesyoudrunk.Wemaketezgüinooutofcorn.(1)Abottleof_____isonthetable.(2)Everyonelikes_____.(3)_____makesyoudrunk.(4)Wemake_____outofcorn.(1)(2)(3)(4)1111100001011110tezgüinomotoroiltortillaswine两行内容十分相近两个单词含义相近编码:让计算机理解人类语言7基于统计的N-gram(1970after)语言模型:技术演化Before:P(小)·P(猫|小)·P(抓|小猫)·P(老|小猫抓)·P(鼠|小猫抓老)3-gram:P(小)·P(猫|小)·P(抓|小猫)·P(老|猫抓)·P(鼠|抓老)2-gram:P(小)·P(猫|小)·P(抓|猫)·P(老|抓)·P(鼠|老)Transformer(2017after)基于神经网络的LSTM/GRU(2000after)8常见的深度学习模型框架,可用于解决Seq2Seq问题可以根据任务选择不同的编码器和解码器(LSTM/GRU/Transformer)EncoderDecoder我很聪明!Iamprettysmart!隐空间RepresentationEncoder-Decoder9一、语言模型三、ChatGPTOutline四、DeepSeek五、新一代智能体二、Transformer10Transformer:理论架构创新•自注意力机制:支持并行计算/全局上下文的理解能力•多头注意力:从多个角度捕捉复杂的语义关系•前馈网络/位置编码/层归一化:解决了传统模型的诸多局限性大型语言模型简史2017JUN1958Transformer2018JUNGPT2018OCTBERT2019FEBGPT-22019OCTT52020MAYGPT-32021SEPFLAN2022MARGPT-3.5InstrutGPT2022NOVChatGPT2023FEBLLaMA2023MARGPT-42024MARGPT-4o2024APRLLaMA-3.1405B2024DECOpenAI-o1DeepSeek-V32025JANDeepSeek-R1https://blog.csdn.net/cf2SudS8x8F0v/article/details/145695146OpenAI-o311NIPS2017,引用量15万+引入全新注意力机制,改变了深度学习模型的处理方式EncoderDecoderTransformer:大模型的技术基座AttentionIsAllYouNeed12Transformer:(自)注意力机制在理解语言任务时,Attention机制本质上是捕捉单词间的关系Theanimaldidn'tcrossthestreetbecauseitwastootired/wideSheiseatingagreenapple.中国南北饮食文化存在差异,豆花有南甜北咸之分。南方人一般喜欢吃甜豆花12313Transformer:(自)注意力机制ImageSketchGradient在理解图像任务时,Attention机制本质上是一种图像特征抽取14Transformer:训练机制场景:你在图书馆想找一本关于“机器学习基础”的书Query:描述要找的书(精准的需求描述)Key:书的索引编号(高效的书籍定位)Value:内容的抽取(由目标任务驱动)https://newsletter.theaiedge.io/p/the-multi-head-attention-mechanism15大型语言模型简史预训练时代:大力出奇迹(“暴力美学”)•BERT:BidirectionalEncoderRepresentationsTransformers•GPT:GenerativePertainedTransformer•自监督算法:MLM/NTP/MAE解决海量数据标注问题2017JUN1958Transformers2018JUNGPT2018OCTBERT2019FEBGPT-22019OCTT52020MAYGPT-32021SEPFLAN2022MARGPT-3.5InstrutGPT2022NOVChatGPT2023FEBLLaMA2023MARGPT-42024MARGPT-4o2024APRLLaMA-3.1405B2024DECOpenA...


 VIP
VIP



