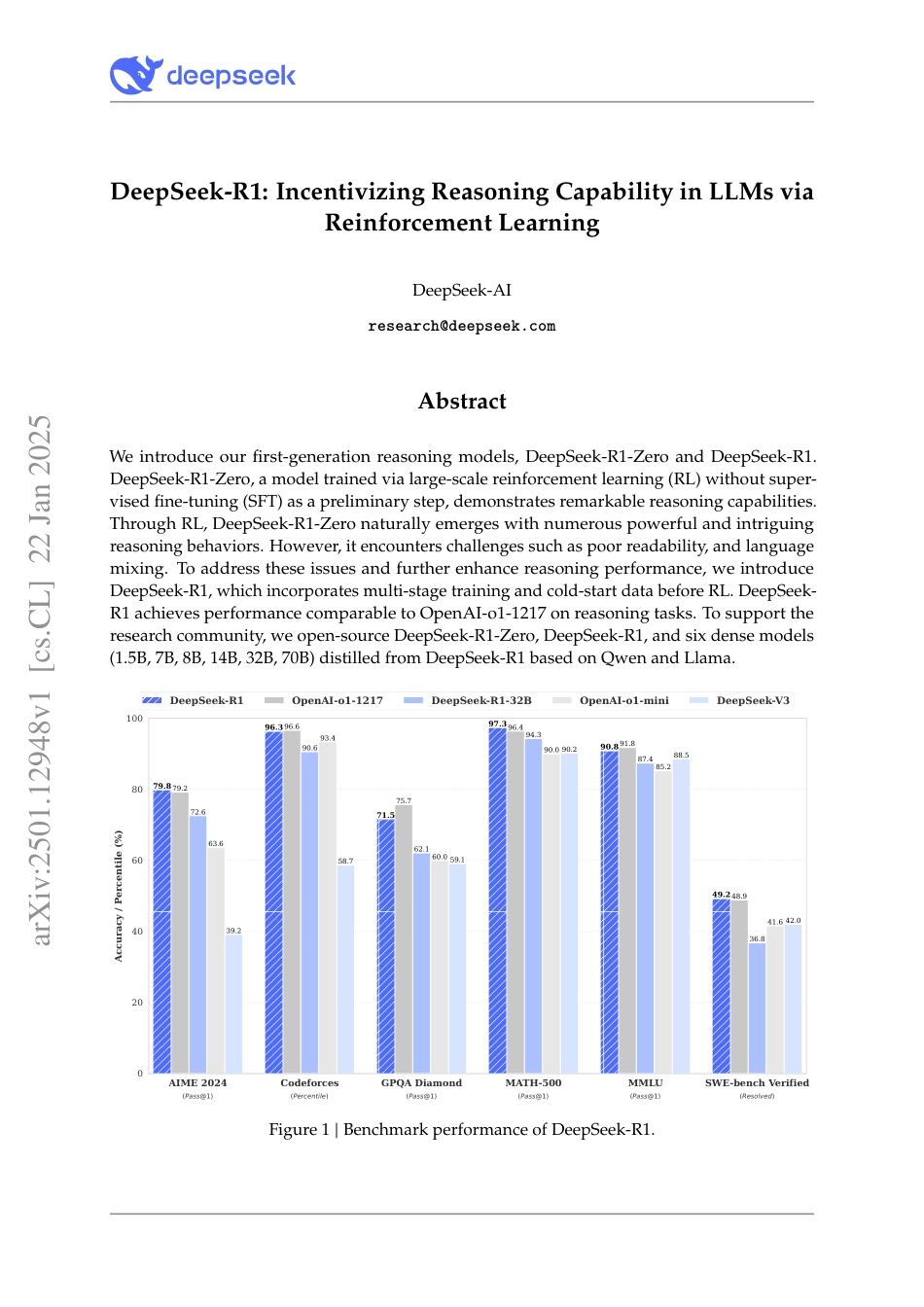
DeepSeek-R1:IncentivizingReasoningCapabilityinLLMsviaReinforcementLearningDeepSeek-AIresearch@deepseek.comAbstractWeintroduceourfirst-generationreasoningmodels,DeepSeek-R1-ZeroandDeepSeek-R1.DeepSeek-R1-Zero,amodeltrainedvialarge-scalereinforcementlearning(RL)withoutsuper-visedfine-tuning(SFT)asapreliminarystep,demonstratesremarkablereasoningcapabilities.ThroughRL,DeepSeek-R1-Zeronaturallyemergeswithnumerouspowerfulandintriguingreasoningbehaviors.However,itencounterschallengessuchaspoorreadability,andlanguagemixing.Toaddresstheseissuesandfurtherenhancereasoningperformance,weintroduceDeepSeek-R1,whichincorporatesmulti-stagetrainingandcold-startdatabeforeRL.DeepSeek-R1achievesperformancecomparabletoOpenAI-o1-1217onreasoningtasks.Tosupporttheresearchcommunity,weopen-sourceDeepSeek-R1-Zero,DeepSeek-R1,andsixdensemodels(1.5B,7B,8B,14B,32B,70B)distilledfromDeepSeek-R1basedonQwenandLlama.AIME2024(Pass@1)Codeforces(Percentile)GPQADiamond(Pass@1)MATH-500(Pass@1)MMLU(Pass@1)SWE-benchVerified(Resolved)020406080100Accuracy/Percentile(%)79.896.371.597.390.849.279.296.675.796.491.848.972.690.662.194.387.436.863.693.460.090.085.241.639.258.759.190.288.542.0DeepSeek-R1OpenAI-o1-1217DeepSeek-R1-32BOpenAI-o1-miniDeepSeek-V3Figure1|BenchmarkperformanceofDeepSeek-R1.arXiv:2501.12948v1[cs.CL]22Jan2025Contents1Introduction31.1Contributions.......................................41.2SummaryofEvaluationResults.............................42Approach52.1Overview..........................................52.2DeepSeek-R1-Zero:ReinforcementLearningontheBaseModel..........52.2.1ReinforcementLearningAlgorithm......................52.2.2RewardModeling................................62.2.3TrainingTemplate................................62.2.4Performance,Self-evolutionProcessandAhaMomentofDeepSeek-R1-Zero62.3DeepSeek-R1:ReinforcementLearningwithColdStart...............92.3.1ColdStart.....................................92.3.2Reasoning-orientedReinforcementLearning.................102.3.3RejectionSamplingandSupervisedFine-Tuning...............102.3.4ReinforcementLearningforallScenarios...................112.4Distillation:EmpowerSmallModelswithReasoningCapability..........113Experiment113.1DeepSeek-R1Evaluation.................................133.2DistilledModelEvaluation...............................144Discussion144.1Distillationv.s.ReinforcementLearning........................144.2UnsuccessfulAttempts..................................155Conclusion,Limitations,andFutureWork16AContributionsandAcknowledgments2021.IntroductionInrecentyears,LargeLanguageModels(LLMs)havebeenundergoingrapiditerationandevolution(Anthropic,2024;Google,2024;OpenAI,2024a),progressivelydiminishingthegaptowardsArtificialGeneralIntelligence(AGI).Recently,post-traininghasemergedasanimportantcomponentofthefulltrainingpipeline.Ithasbeenshowntoenhanceaccuracyonreasoningtasks,alignwithsocialvalues,andadapttouserpreferences,allwhilerequiringrelativelyminimalcomputationalresourcesagainstpre-training.Inthecontextofreasoningcapabilities,OpenAI’so1(OpenAI,2024b)seriesmodelswerethefirsttointroduceinference-timescalingbyincreasingthelengthoftheChain-of-Thoughtreasoningprocess.Thisapproachhasachievedsignificantimprovementsinvariousreasoningtasks,suchasmathematics,coding,andscientificreasoning.However,thechallengeofeffectivetest-timescalingremains...


 VIP
VIP



