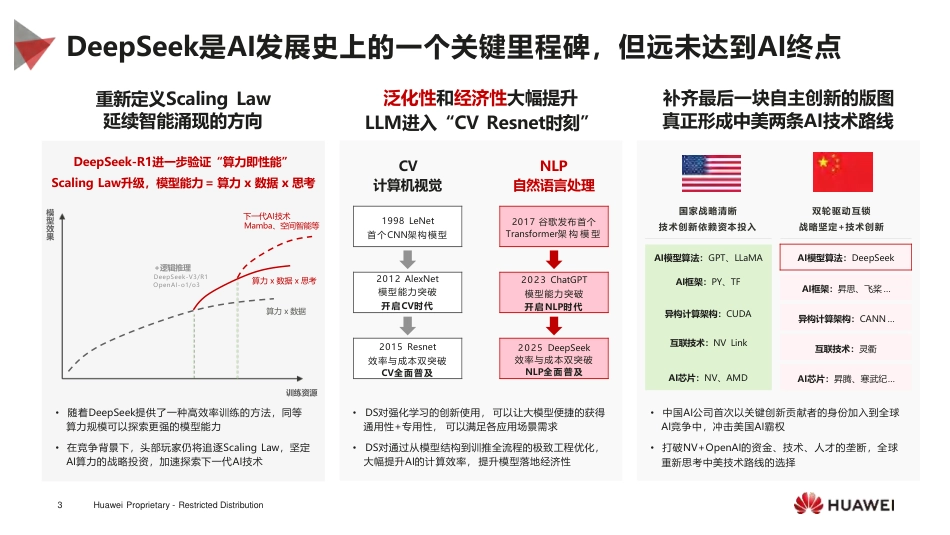
把握DeepSeek时刻,携手同行华为昇腾AI解决方案汇报2025年2月DeepSeek洞察及昇腾适配进展华为昇腾AI基础软硬件介绍CONTENTS目录21HuaweiProprietary-RestrictedDistribution2训练资源•随着DeepSeek提供了一种高效率训练的方法,同等算力规模可以探索更强的模型能力•在竞争背景下,头部玩家仍将追逐ScalingLaw,坚定AI算力的战略投资,加速探索下一代AI技术DeepSeek是AI发展史上的一个关键里程碑,但远未达到AI终点AI模型算法:GPT、LLaMAAI框架:PY、TF异构计算架构:CUDA互联技术:NVLinkAI芯片:NV、AMD•DS对强化学习的创新使用,可以让大模型便捷的获得通用性+专用性,可以满足各应用场景需求•DS对通过从模型结构到训推全流程的极致工程优化,大幅提升AI的计算效率,提升模型落地经济性•中国AI公司首次以关键创新贡献者的身份加入到全球AI竞争中,冲击美国AI霸权•打破NV+OpenAI的资金、技术、人才的垄断,全球重新思考中美技术路线的选择泛化性和经济性大幅提升LLM进入“CVResnet时刻”补齐最后一块自主创新的版图真正形成中美两条AI技术路线AI框架:昇思、飞桨…异构计算架构:CANN…互联技术:灵衢AI芯片:昇腾、寒武纪…DeepSeek-R1进一步验证“算力即性能”ScalingLaw升级,模型能力=算力x数据x思考+逻辑推理DeepSeek-V3/R1OpenAI-o1/o3算力x数据重新定义ScalingLaw延续智能涌现的方向2017谷歌发布首个Transformer架构模型2023ChatGPT模型能力突破开启NLP时代2012AlexNet模型能力突破开启CV时代1998LeNet首个CNN架构模型2025DeepSeek效率与成本双突破NLP全面普及2015Resnet效率与成本双突破CV全面普及AI模型算法:DeepSeek国家战略清晰技术创新依赖资本投入NLP自然语言处理双轮驱动互锁战略坚定+技术创新CV计算机视觉3HuaweiProprietary-RestrictedDistribution下一代AI技术Mamba、空间智能等算力x数据x思考模型效果低成本完美对标OpenAIO1,突破精确语义理解及复杂推理任务DeepSeek-V3是一款MoE模型,总参数量671B,激活参数量37B,采用2048张H800(节点内NVLink,节点间IB,非超节点架构)在14.8Ttoken数据集上基于自研HAI-LLM训练系统总计训练了1394h(58.08天)性能优数学、科学和代码等领域领先业界,成为业界公认的LLM的领先模型来源:DeepSeek模型测试数据&互联网硬件级优化绕过GUDA进行PTX编程计算与通信优化,性能提升30%GRPO:群体进化的智慧筛选器自我验证机制:AI的"错题本系统"混合专家模型的"智能路由器“多头潜在注意力MLA:空间压缩术训练框架加速:16到3的量化压缩,通信降低89%推理加速:预加载,动态批处理等模型、数据、工具链、部署全开源蒸馏技术使能第三方模型性能DeepSeekV3:实现极致性能,稀疏MOE提质降本技术创新硬件级、算法级、架构级、工程级、开源生态5大技术创新,轰动全球低成本绕过CUDA挖掘FP8硬件潜力,MOE和MLA技术实现不到10%的成本方案~150M$5.57M$DeepSeek–V3训练成本Llama3.1-405B训练成本DeepSeek-R1推理成本仅为OpenAIo1的3%算法革命架构创新工程奇迹开源生态4HuaweiProprietary-RestrictedDistributionDeepSeekR1:在Reasoning任务达到了世界水平(OpenAI-o1)以2阶段SFT+2阶段RL完成,从而解决R1-Zero可读性差、多种语言混合问题本次开源同时发布了6个基于DeepSeek-R1蒸馏的更小稠密模型(Qwen/LLaMa1.5B7B14B32B70B)DeepSeek-R1以DeepSeek-V3Base(671B)为基础模型,使用GRPO算法作为RL框架来提升Reasoning性能HuaweiProprietary-RestrictedDistribution5张量低秩压缩以降低KVCache资源开销:相比于传统MHA,MLA通过降维操作使得存储的张量维度大幅减小。(下图中仅红色阴影部分需要存储)(bs,ℎ)(bs,ℎ)2bsℎ(bs,ℎ)(bs,ℎ)bsℎ′压缩后宽度ℎ′≪隐藏层宽度ℎMLA架构:1)分别对Query、Key-Valuepair进行低秩压缩;2)使用RoPE获得位置信息;3)使用MHA计算得到输出。对6DeepSHwkevir而opr言ietryn-sritd,DMistriLbti可on以将KVCache降低为=1.7%只需存储图中的cv,K即可;考虑到矩阵乘法结合律,具体实现过程中WUK可以与WUQ融合、WUV可以与Wo融合,从而无需为每个query计算key-value值。tRtK相比于MHA,MLA每token...


 VIP
VIP



