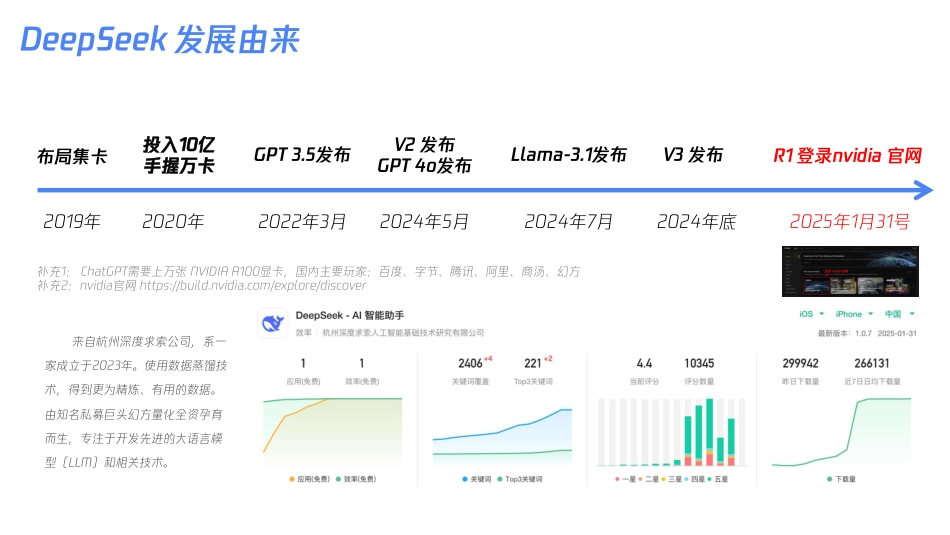
DeepSeek是什么DeepSeek是杭州深度求索人工智能基础技术研究有限公司推出的一款创新大语言模型。公司成立于2023年7月17日,由知名私募巨头幻方量化孕育而生。DeepSeek致力于开发和应用先进的大语言模型技术深度小助手聪明且低成本聪明强大能干中国本土AI深度思考联网搜索DeepSeek:大语言模型的特点有哪些?内容token化大模型看到的世界与人看到的不太一样训练前需要将文本进行处理,比如切割称为Token的基本单元;比如问ai一个英文单词illegal中有几个字母l,有些指令模型回答为2个;但deepseekr1推理模型是可以回答正确!模型训练存在endtime大模型训练语料存在一个截止时间deepseekR1虽然是25年1月发布,但它的知识库截止日期是2023年12月,这就意味着ds可以提供在此日期发布之前的公开信息和常识;需要经过大量清洗、监督微调、反馈强化学习。但对于之后的新闻、事件变化、新事物则无法直接获取或验证。解决办法是开启联网模式或提示词中补充说明无自我认识无自我意识网上有个段子是“有人问deepseek你是谁,然后回答是gpt”目前AI大模型不知道自己是谁,也不知道自己是采用什么模型。除非是厂商在后期再微调、或再训练,如果大家问到类似的问题,可能目前的AI大模型会回答错误。解决办法是少问AI是谁、采用什么模型上下文长度限定记忆力有限AI大模型目前的记忆力大概是64k~128k目前AI大模型均有上下文长度限定;deepseekr1提供64ktoken上下文长度,对应中文的话大约3万~4万字。目前还不能一次性投喂太长的文档给它,比如:一本完成西游记、或者非常长的文档让它翻译,AI它是没有办法完整读完解决办法是分成多次投喂回答输出长度有限AI大模型目前的回答4k~8k,2000~4000字目前AI大模型无法一次性完成万字长文,也无法一次性输出5千字,均是模型输出长度限制所致;如果是输出长文,可以尝试先让AI大模型先生成一个目录,然后再根据目录输出对应模块;如果是长文翻译类,则多次输入,或者拆解后多次调用API解决办法是将任务分解成多次2019年2020年投入10亿手握万卡2022年3月GPT3.5发布布局集卡补充1:ChatGPT需要上万张NVIDIAA100显卡,国内主要玩家:百度、字节、腾讯、阿里、商汤、幻方补充2:nvidia官网https://build.nvidia.com/explore/discoverV2发布GPT4o发布V3发布2024年底2024年5月Llama-3.1发布2024年7月2025年1月31号R1登录nvidia官网DeepSeek发展由来来自杭州深度求索公司,系一家成立于2023年。使用数据蒸馏技术,得到更为精炼、有用的数据。由知名私募巨头幻方量化全资孕育而生,专注于开发先进的大语言模型(LLM)和相关技术。DeepSeek为什么火:一个足够优秀的模型变得人人免费拥有一、技术突破:为什么DeepSeek的模型值得关注?二、开源生态:DeepSeek如何改变开发者社区?三、行业落地:DeepSeek推动的技术范式迁移四、行业竞争格局:DeepSeek的“鲶鱼效应”1.模型架构与训练效率优化架构改进:MLA多层注意力架构、FP8混合精度训练框架、DualPipe跨节点通信训练策略:采用混合精度训练(BF16+FP8)和梯度累积策略2.数据质量与领域适配数据筛选:多模态数据清洗领域微调:“领域渐进式微调”(ProgressiveDomainFine-tuning)策略1.开放模型与工具链全量开源:DeepSeek开源了完整训练代码、数据清洗Pipeline和领域微调工具包(如DeepSeek-Tuner),极大降低复现和二次开发门槛轻量化部署:提供模型压缩工具(如4-bit量化适配TensorRT-LLM)2.社区驱动创新开发者基于DeepSeek模型快速构建垂直应用金融场景教育场景1.从“通用模型”到“领域专家”传统大模型(如GPT-3.5)依赖PromptEngineering适配行业需求,而DeepSeek通过预训练阶段嵌入领域知识,减少后期微调成本2.成本革命通过模型压缩和高效推理框架,企业可基于单卡部署专业模型,推理成本降至GPT-4API的1/50如:某电商客服系统用DeepSeek-7B替代GPT-4,单次交互成本从0.06降至0.001,日均处理量提升10倍。1.倒逼闭源模型降价DeepSeek的开源策略迫使国际厂商调整定价。例如,Anthropic的Claude3SonnetAPI价格在DeepSeek开源后下调2.催化国产AI芯片生态DeepSeek与华为昇腾、寒武纪等厂商深度合作,优化模型在...


 VIP
VIP



