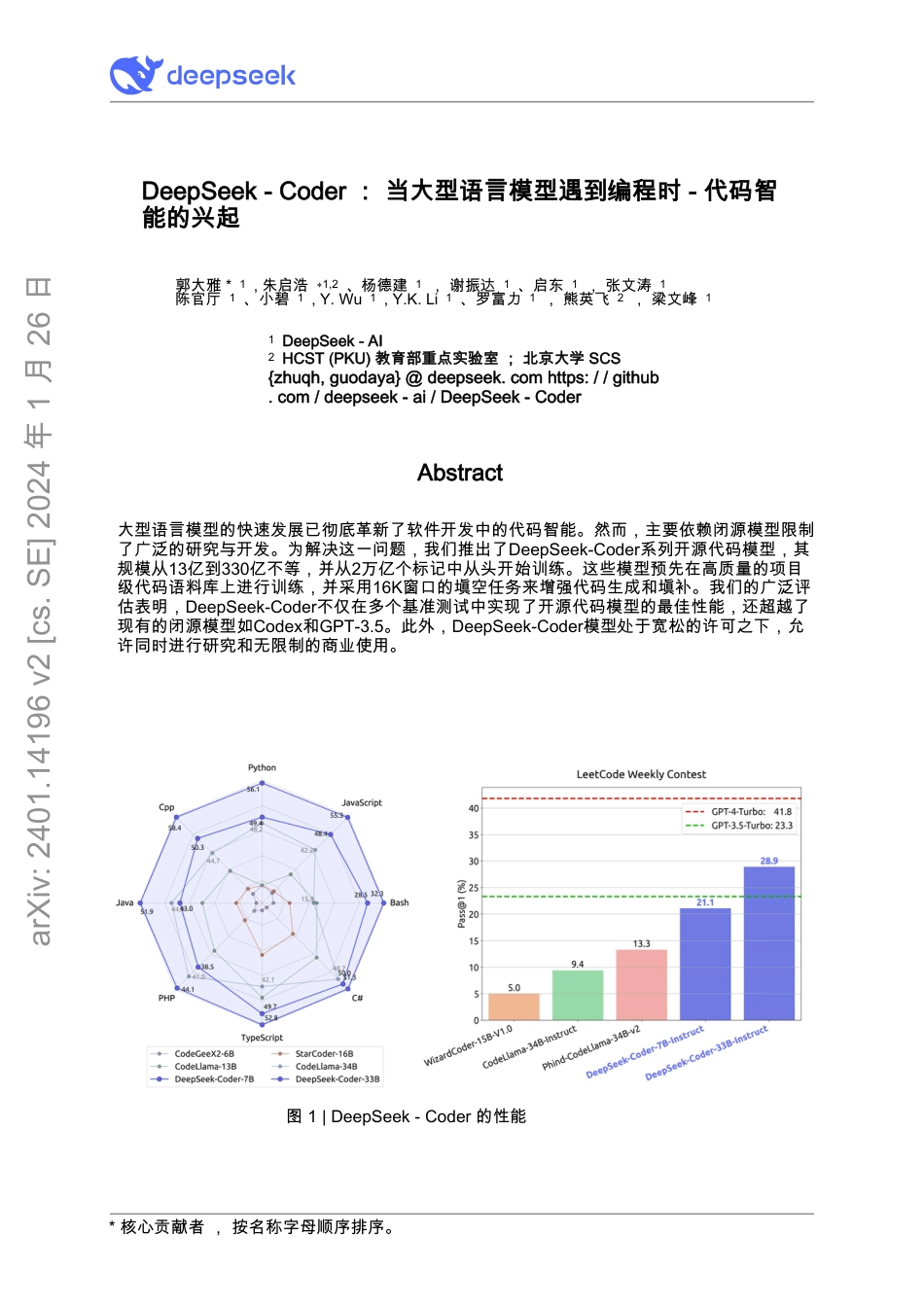
图1|DeepSeek-Coder的性能Abstract*核心贡献者,按名称字母顺序排序。arXiv:2401.14196v2[cs.SE]2024年1月26日大型语言模型的快速发展已彻底革新了软件开发中的代码智能。然而,主要依赖闭源模型限制了广泛的研究与开发。为解决这一问题,我们推出了DeepSeek-Coder系列开源代码模型,其规模从13亿到330亿不等,并从2万亿个标记中从头开始训练。这些模型预先在高质量的项目级代码语料库上进行训练,并采用16K窗口的填空任务来增强代码生成和填补。我们的广泛评估表明,DeepSeek-Coder不仅在多个基准测试中实现了开源代码模型的最佳性能,还超越了现有的闭源模型如Codex和GPT-3.5。此外,DeepSeek-Coder模型处于宽松的许可之下,允许同时进行研究和无限制的商业使用。DeepSeek-Coder:当大型语言模型遇到编程时-代码智能的兴起1DeepSeek-AI2HCST(PKU)教育部重点实验室;北京大学SCS{zhuqh,guodaya}@deepseek.comhttps://github.com/deepseek-ai/DeepSeek-Coder郭大雅*1,朱启浩∗1,2、杨德建1,谢振达1、启东1,张文涛1陈官厅1、小碧1,Y.Wu1,Y.K.Li1、罗富力1,熊英飞2,梁文峰121.Introduction为了应对这一挑战,我们推出了DeepSeek-Coder系列。该系列包括一系列开源代码模型,规模从13亿到33亿不等,涵盖每个规模的基版本和指令版本。每个系列中的模型均从87种编程语言中提取的2万亿个标记重新训练,确保对编程语言和语法有全面的理解。此外,我们尝试在仓库级别组织预训练数据,以增强模型在仓库内部跨文件上下文中的理解能力。除了在预训练过程中使用下一个标记预测损失外,我们还引入了Fill-In-Middle(FIM)方法(Bavarianetal.,2022;Lietal.,2023)。这种方法旨在进一步提升模型的代码完成能力。为满足处理更长代码输入的要求,我们将上下文长度扩展到16K。这一调整使我们的模型能够处理更加复杂和广泛的编码任务,从而增强了其在各种编码场景中的适用性和灵活性。软件开发领域因大型语言模型的迅速进步(OpenAI,2023;Touvronetal.,2023)而得到了显著转型,这些模型带来了代码智能的新时代。这些模型有可能自动化和简化许多编码方面的工作,从错误检测到代码生成,从而提高生产力并减少人为错误的可能性。然而,该领域的重大挑战之一是在开源模型(Lietal.,2023;Nijkampetal.,2022;Rozieretal.,2023;Wangetal.,2021)与闭源模型(GeminiTeam,2023;OpenAI,2023)之间的性能差距。尽管巨型闭源模型非常强大,但由于其专有性质,许多研究人员和开发者仍然难以访问这些模型。我们使用多种公开的代码相关基准进行了全面的实验。研究发现,在开源模型中,DeepSeek-Coder-Base33B在所有基准测试中均表现出优越的性能。此外,OpenAIGPT-3.5TurboCoder-Instruct33B超越在大多数评估基准中,OpenAIGPT-4显著缩小两者之间的性能差距并且采用了开源模型。令人惊讶的是,尽管参数量较少,DeepSeek-Coder-Base7B在与参数量大五倍的模型(如CodeLlama-33B)相比时仍能展现出竞争力的表现(Roziereetal.,2023)。总结来说,我们的主要贡献是:•我们引入了DeepSeek-Coder-Base和DeepSeek-Coder-Instruct,这两种先进的代码集中型大型语言模型(LLMs)。通过广泛训练于庞大的代码语料库,这些模型展示了对87种编程语言的理解能力。此外,它们还提供了多种模型规模以满足不同计算和应用需求。我们首次尝试在模型构建过程中纳入仓库级别的数据。•我们的模型预训练阶段。我们发现这可以显著提升跨文件代码生成的能力。•我们的研究严格分析了FIM训练策略对代码模型预训练阶段的影响。这些全面的研究结果揭示了FIM配置的一些有趣方面,提供了宝贵的见解,极大地促进了代码预训练模型的改进和发展。•我们对我们的代码LLM进行了广泛的评估,涵盖了多种代码相关任务的广泛基准。研究发现表明,DeepSeek-Coder-Base在这些基准上超越了所有现有的开源代码LLM。此外,3图2|创建数据集的过程2.1.GitHub数据抓取和过滤2.数据收集2.2.DependencyParsingData爬行依赖关系解析回购级重复数据删除质量筛选Rule过滤首先,我们过滤掉平均行长度超过100字符或最大行长度超过1000字符的文件。此外,我们去除...





 VIP
VIP
